
Introduction
The rise of Vision-Language-Action (VLA) models is transforming how robots learn to interact with the world. These multi-modal models take in visual observations and natural language instructions to output robot actions, enabling robots to perform complex tasks with unprecedented flexibility and generalization. However, the performance of VLA models hinges entirely on the quality, diversity, and scale of training data. Collecting large volumes of high-quality demonstration data using real robots is often slow, costly, and prone to hardware wear and safety risks.
Markerless motion capture (mocap) has emerged as a powerful solution to this bottleneck. The Virdyn YanDong Markerless Motion Capture System allows researchers to quickly and efficiently capture natural human demonstrations, which can then be converted into structured data for training VLA policies. This article details how YanDong enables end-to-end VLA data collection, from capturing human actions to generating the final multi-modal datasets.

What is VLA Data Collection?
VLA (Vision-Language-Action) data collection is the process of gathering paired multi-modal data to train robot learning models. A complete VLA dataset consists of three core components:
| Component | Description |
|---|---|
| Vision (V) | High-resolution images or videos of the scene from the robot’s perspective, capturing object positions, environment states, and task context. |
| Language (L) | Natural language instructions, descriptions, or annotations that define the task objective (e.g., “Pick up the blue cup and place it on the tray”). |
| Action (A) | Sequential motion data representing the actions performed, typically consisting of 3D joint trajectories, end-effector poses, or robot control commands. |
Traditional VLA data collection requires running the physical robot for thousands of trials, which is time-consuming and expensive. Using human demonstrations captured via motion capture is a proven alternative to rapidly generate large-scale datasets.

The Role of YanDong Markerless Mocap in VLA Data Collection
The YanDong system is uniquely suited for VLA research due to its wearable-free, markerless design and high-precision full-body + finger tracking. This allows human demonstrators to perform tasks naturally in unconstrained environments, producing realistic and diverse motion data that is critical for training robust policies.
The End-to-End VLA Data Collection Workflow with YanDong
The process is divided into five key stages, from capture to dataset export.
Step 1: Natural Human Demonstration Capture
The core advantage of YanDong is its ability to capture demonstrations without requiring the performer to wear suits, markers, or helmets.
- Setup: Deploy the 7 YanDong industrial cameras in a 4m×4m capture volume.
- Demonstration: A human performer executes the target task (e.g., grasping, placing, assembling) in the scene.
- Multi-modal Capture: The system simultaneously records:
- Motion Data: Real-time 3D skeletal tracking (21 body joints + 30 finger joints) at up to 60fps with <80ms latency.
- Visual Data: Synchronized RGB video streams from multiple camera viewpoints, including an egocentric perspective mimicking the robot’s camera.
Step 2: AI-Powered Motion Data Processing & Skeleton Solving
Raw motion data is automatically processed into clean, structured action trajectories using YanDongFang software.
- AI Human Reconstruction & Skeleton Solving: The system reconstructs a 3D human model and solves for joint angles in real time.
- Forward/Inverse Kinematics: Kinematic solvers ensure biomechanical consistency, correcting for any tracking artifacts.
- Temporal Transformer Smoothing: A transformer-based algorithm filters noise and jitter, producing smooth, natural motion trajectories.
The output is a continuous sequence of joint positions and orientations that accurately represent the human’s actions.
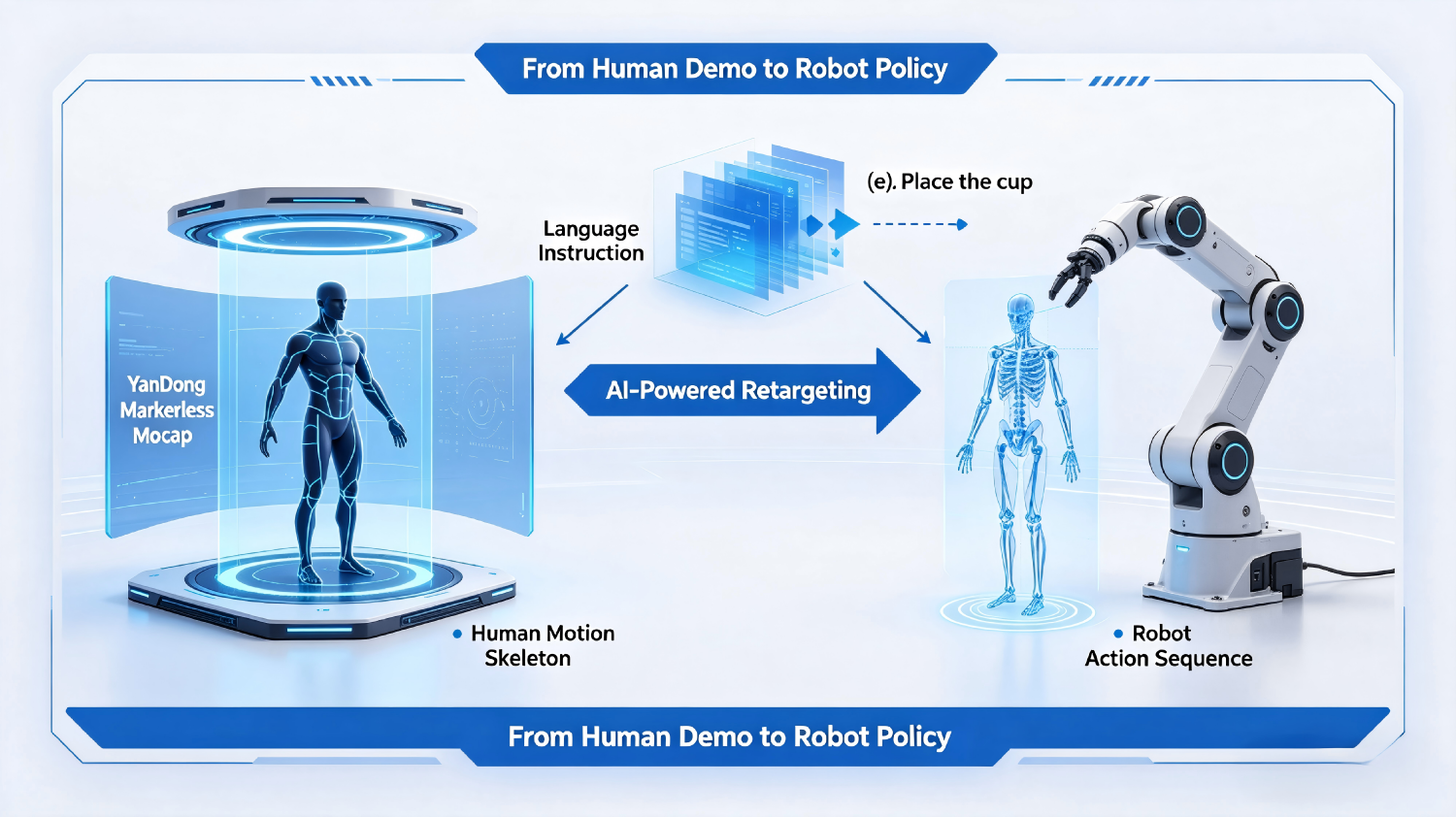
Step 3: Action-to-Robot Retargeting
To make the human data usable for robot training, it must be adapted to the target robot’s kinematic structure.
- Skeleton Retargeting: The human motion skeleton is mapped to the robot’s skeleton using dedicated tools like Virdyn VDRobot Studio.
- End-Effector Pose Extraction: For manipulation tasks, the 3D position and orientation of the human hand are extracted and converted into robot gripper poses.
- Joint Limit Clamping: The motion is adjusted to respect the robot’s physical joint limits, preventing infeasible or damaging trajectories.
The result is a robot-agnostic action sequence that can be exported in standard formats like CSV (LaFAN).
Step 4: Multi-Modal Data Annotation & Pairing
This is where the motion and visual data are combined with language to form complete VLA samples.
- Language Instruction Annotation: Each demonstration sequence is paired with one or more natural language commands. This can be done manually or semi-automatically.Time-Sync Alignment: The language labels are aligned with the corresponding visual frames and action trajectories based on timestamps.
- Example: The video clip of placing a mug is annotated with “Place the mug on the table.”
- Segmentation: Long demonstrations are split into individual task steps to create diverse training samples.
Step 5: Dataset Export & Format Standardization
The final step is to export the curated multi-modal data into a format compatible with popular robot learning frameworks.
- Supported Formats: Export as ROS bags, HDF5, or custom formats compatible with PyTorch/TensorFlow.
- Metadata Packaging: Include camera intrinsics, timestamps, robot URDF information, and language embeddings (if pre-computed).
- Direct Use in Simulation: The dataset is ready to be imported into simulators like Isaac Lab or MuJoCo for reinforcement learning and imitation learning training.
Key Advantages of YanDong for VLA Research
Using YanDong markerless mocap for VLA data collection offers significant benefits over traditional methods:
| Advantage | Description |
|---|---|
| High-Fidelity Action Capture | Captures fine-grained finger and body movements with precision, critical for learning dexterous manipulation tasks. |
| Rapid Dataset Generation | Collect hundreds of demonstrations per day, without the slow cycle times and downtime associated with physical robots. |
| Diverse and Natural Demonstrations | The wearable-free design allows for a wider range of natural human behaviors, leading to more generalizable policies. |
| Reduced Cost & Risk | Eliminates robot wear, maintenance, and safety risks during data collection, drastically lowering research overhead. |
| Seamless Simulation Integration | Exported data is directly compatible with leading simulation environments, enabling fast Sim2Real transfer pipelines. |
| Permanent Licensing | Unlike subscription-based services, YanDong offers a one-time purchase with unlimited usage, making it ideal for long-term research projects. |

Conclusion
[/prisna-wp-translate-show-hide
Building robust Vision-Language-Action models requires large, high-quality, and diverse datasets. The Virdyn YanDong Markerless Motion Capture System provides a powerful, efficient, and cost-effective pipeline for VLA data collection. By enabling researchers to easily capture, process, and annotate human demonstrations, YanDong accelerates the development of the next generation of intelligent, interactive robots.
For labs and institutions looking to scale their robot learning research, YanDong is not just a motion capture tool—it’s a gateway to building better, more capable VLA models.
VLA data collection, Vision-Language-Action dataset, markerless motion capture for robotics, human demonstration data collection, robot imitation learning dataset, dexterous manipulation data, action-to-robot retargeting, robot learning with motion capture
Post time: May-12-2026